
Scopri cos'è l'ETL (Extract/Transform/Load), il suo funzionamento, i vantaggi e le best practice per l'integrazione dei dati aziendali. Una guida dettagliata per esperti e principianti.
ETL è un acronimo che sta per Extract, Transform, Load. Questo processo viene utilizzato per raccogliere dati da diverse fonti, trasformarli in un formato appropriato e poi caricarli in un sistema di destinazione, come un database o un data warehouse.
L'ETL è essenziale per l'integrazione dei dati perché permette di unificare informazioni provenienti da diverse fonti in un unico luogo. Questo è particolarmente importante nelle aziende, dove i dati possono essere sparsi tra vari sistemi e formati.
L'estrazione è la prima fase del processo ETL e consiste nel raccogliere i dati dalle varie fonti. Questo passaggio è fondamentale perché se i dati iniziali non sono corretti o completi, anche il risultato finale sarà compromesso.
Fonti dei dati - Le fonti possono essere database relazionali, file flat (come CSV o Excel), applicazioni web, API (Application Programming Interface), e molti altri. Ogni fonte può avere un formato e una struttura diversa.
Metodi di estrazione - Esistono diversi metodi per estrarre i dati:
La trasformazione è il cuore del processo ETL. Durante questa fase, i dati estratti vengono puliti, filtrati e modificati per adattarsi ai requisiti del sistema di destinazione.
Pulizia e normalizzazione dei dati - I dati grezzi possono contenere errori, duplicati o essere in formati incoerenti. La pulizia dei dati implica la correzione o l'eliminazione di questi problemi. La normalizzazione può significare la conversione dei dati in un formato standardizzato.
Aggregazione e arricchimento dei dati - Questo passaggio può includere il calcolo di somme, medie, o altre statistiche, così come l'aggiunta di dati mancanti da altre fonti. Ad esempio, potresti arricchire un set di dati di clienti aggiungendo informazioni geografiche basate sui codici postali.
L'ultima fase del processo ETL è il caricamento dei dati trasformati nel sistema di destinazione. Questo sistema è spesso un data warehouse o un altro database progettato per l'analisi e la reportistica.
Tipi di destinazioni - Le destinazioni possono includere database relazionali, data warehouse, data mart, sistemi di business intelligence e altro ancora.
Tecniche di caricamento - Esistono vari metodi per caricare i dati:
Nel panorama attuale, esistono numerosi strumenti e tecnologie che possono aiutare a implementare il processo ETL. Questi strumenti variano per funzionalità, complessità, costo e facilità d'uso. È importante scegliere lo strumento giusto in base alle esigenze specifiche della tua organizzazione.
Ecco alcuni dei più noti strumenti ETL disponibili sul mercato:
Quando si sceglie uno strumento ETL, è importante considerare se optare per una soluzione open source o commerciale. Ecco un confronto tra i due:
Vantaggi:
Svantaggi:
Vantaggi:
Svantaggi:
La scelta tra strumenti open source e commerciali dipende dalle specifiche necessità della tua organizzazione, dal budget disponibile e dalla complessità dei tuoi processi di integrazione dei dati.
Implementare un processo ETL efficace richiede pianificazione e attenzione ai dettagli. Seguire le best practice può aiutare a garantire che il processo ETL sia efficiente, affidabile e scalabile.
Pianificazione del Processo ETL
Una buona pianificazione è essenziale per il successo di un progetto ETL. Ecco alcuni passaggi chiave:
Monitoraggio e Gestione della Qualità dei Dati
La qualità dei dati è fondamentale per ottenere risultati accurati e affidabili. Ecco alcune best practices per garantire la qualità dei dati:
Ottimizzazione delle Performance
Un processo ETL efficiente deve essere ottimizzato per gestire grandi volumi di dati senza rallentamenti. Ecco come:
Per migliorare le nostre capacità di analisi e di reporting, in SAEP ICT sfruttiamo i vantaggi offerti dall’integrazione dei servizi di Google Cloud Platform per estrarre, trasformare e caricare i dati in modo veloce, efficiente e sicuro. Sia che si tratti di processi schedulati regolari o di eventi in tempo reale, le nostre soluzioni si basano su un’architettura flessibile e scalabile, adatta alle esigenze aziendali. Ecco due semplici use case.
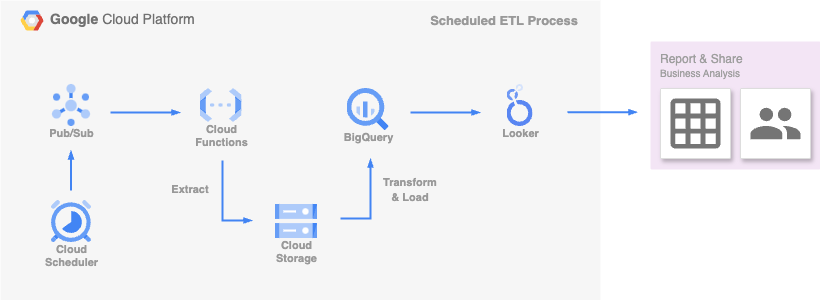
Per gestire processi di analisi paralleli che condividono le medesime modalità di elaborazione dei dati, predisponiamo una Cloud Function centralizzata attivabile da uno o più oggetti Cloud Scheduler tramite Trigger Pub/Sub.
Ogni Scheduler, configurato per eseguire i job in orari differenti a seconda delle necessità, si occupa di invocare la Cloud Function specificando informazioni quali le fonti di estrazione, le modalità di trasformazione e le destinazioni di caricamento dei dati. Sulla base di questi parametri, la Cloud Function processa i dati disponibili su Cloud Storage in diversi formati (es. Excel, JSON, CSV) caricandoli all’interno di un database SQL come BigQuery.
Infine, grazie a Looker Studio è possibile connettersi a BigQuery per creare report e dashboard facilmente condivisibili agli utenti. Questo processo ci permette di mantenere una routine di caricamento dei dati puntuale e precisa, garantendo report sempre aggiornati e affidabili./p
Event Based ETL Process
Per ricevere alert in tempo reale di eventi critici sullo stato delle nostre infrastrutture a microservizi, orchestrate tramite Google Compute Engine (GCE) e Google Kubernetes Engine (GKE), utilizziamo Cloud Monitoring per monitorare le metriche e i log applicativi raccolti da Cloud Logging./p

Al verificarsi di condizioni specifiche, stabilite nelle nostre policies di monitoraggio, vengono creati dei trigger Pub/Sub che attivano le Cloud Function adibite all’estrazione, alla trasformazione e al caricamento dei dati su un database NoSQL come Firestore e all’invio di messaggi di notifica tempestivi tramite Google Chat e Gmail. Questo flusso ci consente di rispondere prontamente a situazioni critiche, assicurando che le informazioni rilevanti siano immediatamente disponibili e comunicate ai team interessati./p










